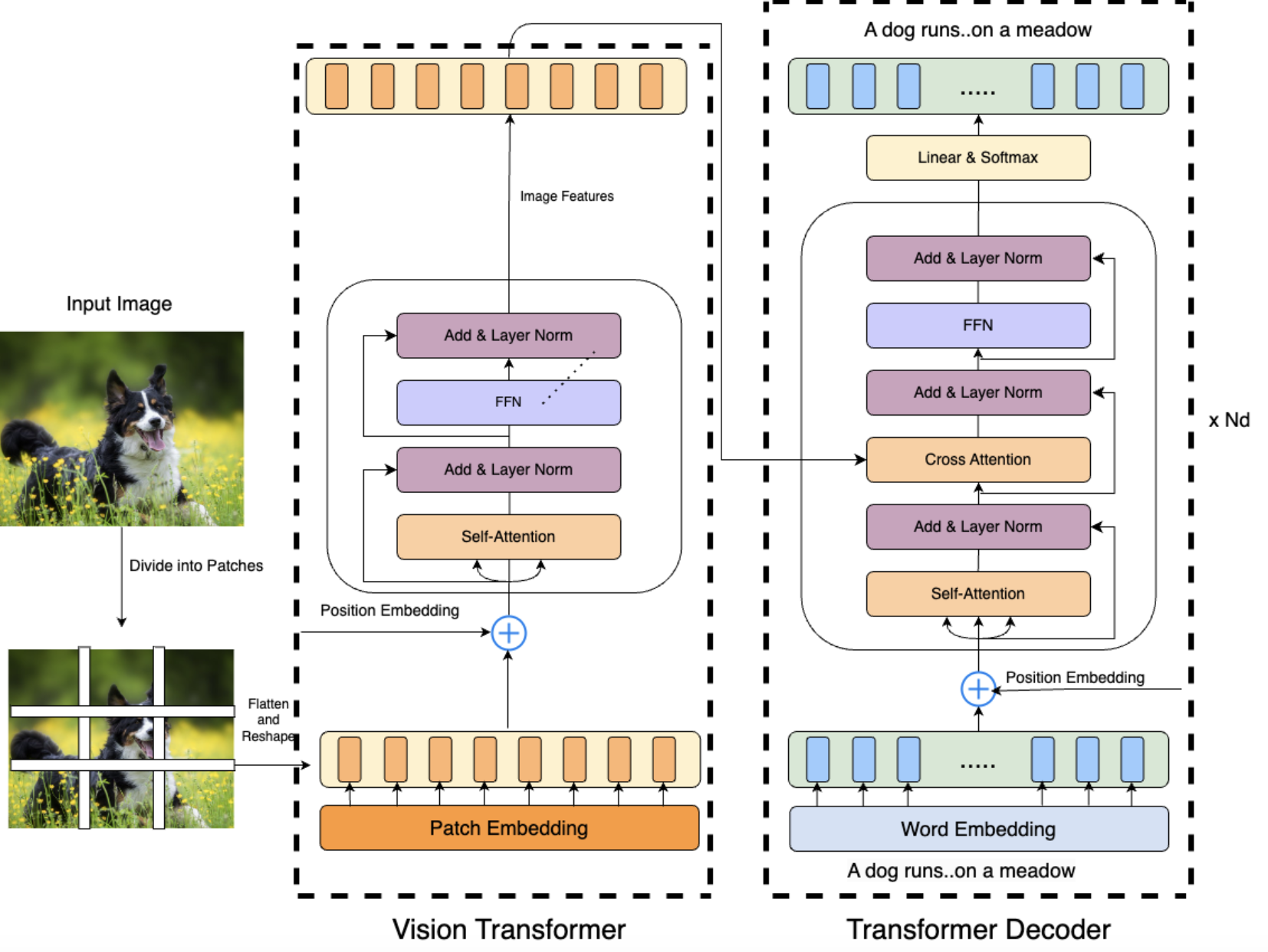
- Extracted image embeddings with a pre‑trained Vision Transformer encoder.
- Trained a Transformer decoder on GloVe token embeddings to generate captions.
- Reached BLEU‑4 = 19.6—competitive with CNN‑based baselines.
- Out‑of‑the‑box inference wrapper enables accessibility alt‑text generation.