YOU CAN REPLICATE THIS PROJECT -> https://github.com/Nagharjun17/Multimodal-Architecture-Optimisation-on-RTX3060-using-TVM
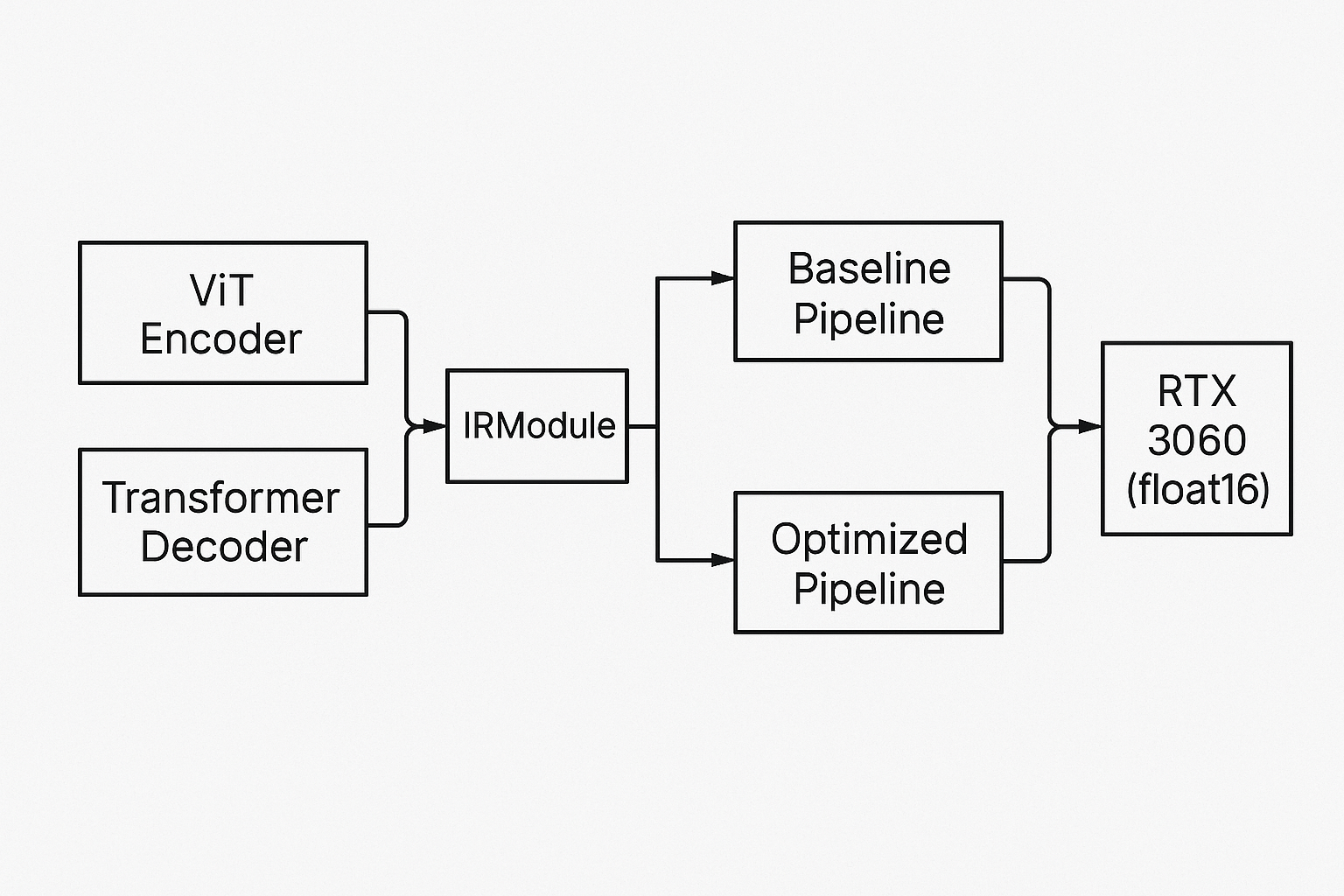
- Built a Vision Transformer encoder + transformer decoder pipeline in TVM Relax (random weights).
- Compiled two pipelines on RTX 3060 (float16):
- baseline_3060 is default legalization/fusion schedule
- opt_vit2txt is optimized with dlight scheduling for matmuls & reductions
- Benchmarked encode and single-token decode:
- Encode: 666.5 ms → 24.4 ms (96% faster)
- Decode: 744.5 ms → 22.6 ms (97% faster)
- Demonstrated full flow: IRModule export to compilation to CUDA execution.