YOU CAN REPLICATE THIS PROJECT -> https://github.com/Nagharjun17/CUDA-Custom-Kernels
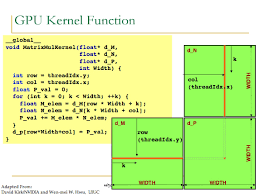
- Implemented custom CUDA kernels (vec_add, matmul_naive, matmul_tiled) with a C++ timing harness using CUDA events (RTX 3060, CUDA 12.x).
- Achieved ~1.3× speedup with shared-memory tiling (e.g., 1024³: 786 → 1038 GFLOPs; 4096³: 839 → 1116 GFLOPs).
- Automated benchmarking pipeline with CSV logging and performance plots (GFLOPs vs. size).
- Profiled kernels using Nsight Compute to analyze occupancy and memory coalescing.